참고사항
본 글은 2018년에 기술 조사를 진행하면서 확인한 내용으로, 최신 상황에 맞게 업데이트 하였으나 일부 부족한 내용이 있을 수 있습니다.
빅데이터나 하둡 관련 전문가가 아니기 때문에 셋팅과 기본적인 사용 외에, 하둡과 관련 생태계 운영의 트러블 슈팅은 잘 모릅니다.
오픈소스 특성상 직접 조사하고 해결해야 하는 부분이 많습니다. 기본 셋팅 관련해서 참고만 부탁 드립니다.
HDP Sandbox의 HDFS에 데이터를 업로드 하는 절차와 방법에 대해 정리한다.
HDP Sandbox에 대한 소개와 설치 스크립트 다운로드는 다음 포스팅을 참고한다.
HDP Sandbox 소개와 Docker 셋팅 파일 다운로드
참고사항 본 글은 2018년에 기술 조사를 진행하면서 확인한 내용으로, 최신 상황에 맞게 업데이트 하였으나 일부 부족한 내용이 있을 수 있습니다. 빅데이터나 하둡 관련 전문가가 아니기 때문에
www.bearpooh.com
HDP Sandbox 2.6.5 버전을 Docker로 설치하는 방법은 다음 포스팅을 참고한다.
HDP Sandbox 2.6.5 Docker 설정과 Ambari 로그인하기
참고사항 본 글은 2018년에 기술 조사를 진행하면서 확인한 내용으로, 최신 상황에 맞게 업데이트 하였으나 일부 부족한 내용이 있을 수 있습니다. 빅데이터나 하둡 관련 전문가가 아니기 때문에
www.bearpooh.com
HDFS는 Hadoop Distributed File System의 약자로 하둡에서 제공하는 파일 시스템이다.
아래와 같이 Docker 컨테이너 내부에서 하둡과 HDFS가 동작 중이므로, PC의 데이터를 HDFS로 업로드해야 하둡에서 사용 가능하다.

로컬의 CSV 파일을 Hadoop의 HDFS에 업로드하고, 업로드한 CSV 파일을 Zeppelin에서 Spark 코드로 사용 가능한지 테스트하는 환경을 구성한다.
일반적으로 Spark은 Parquet, ORC, JSON, CSV 포맷을 지원하므로 해당 포맷으로 테스트를 진행할 것을 권장한다.
본 포스팅에서는 업로드만 다루고, Zeppelin에서 사용하는 방법은 별도 포스팅으로 진행한다.
테스트 목적의 소규모 데이터를 컨테이너에 고정적으로 보관하려는 경우 아래 사항을 참고한다.
- 데이터셋을 변환하는 과정을 테스트 하기 위한 가상의 데이터는 생성하기 어렵고 상당히 번거롭다.
- 범용으로 사용할 테스트 데이터는 외부에 공개 된 예제 데이터 (토이 데이터)를 활용한다.
- 특정 데이터를 테스트에 사용해야 하는 경우 실제 데이터의 일부 (100~1000개)를 샘플링하고, 실제 환경과 동일한 경로로 구성하여 사용한다.
HDP Sandbox 컨테이너 실행
HDP Sandbox의 HDFS에 파일을 업로드 하기 위해서는 HDP Sandbox 컨테이너가 구동 중이어야 한다.
아래 명령으로 HDP Sandbox 컨테이너를 실행한다.
# HDP Sandbox 컨테이너를 실행한다.
$ docker start sandbox-hdp
# HDP Sandbox-proxy 컨테이너를 실행한다.
$ docker start sandbox-proxy
업로드하려는 데이터 파일 개수가 적은 경우
기본적으로 Ambari에서 파일 업로드 기능을 제공하므로, 파일 1~2개는 Ambari의 웹 UI를 통해 업로드하면 된다.
아래 URL을 이용하여 Ambari에 접속한다.
우측 상단의 ▦ 모양을 클릭하고 Files View를 선택한다.
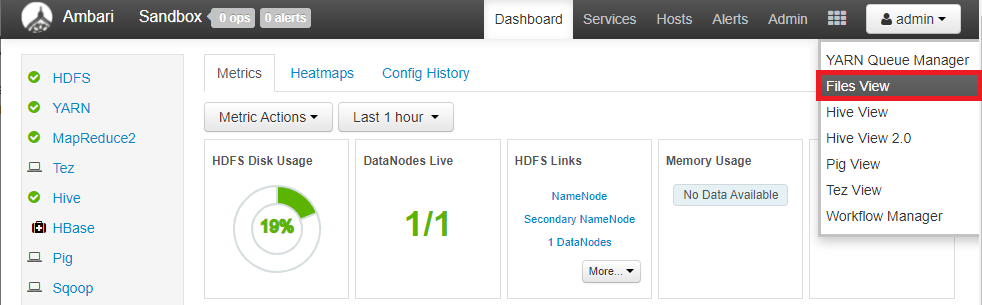
우측 상단의 New Folder를 클릭한다.

업로드 하려는 파일을 저장할 폴더를 생성한다.
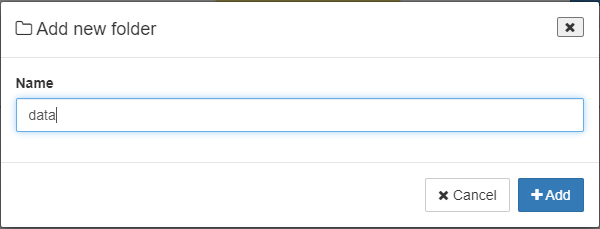
생성한 폴더 하위에 추가 폴더를 생성하려면, 생성한 폴더를 더블 클릭하고 다시 New Folder를 클릭하여 폴더를 생성한다.

우측 상단의 Upload를 클릭한다.

업로드 하려는 파일을 드래그앤드롭 한다.
우측 하단에 현재 단일 파일만 업로드 가능하다고 되어 있다.

점선 안쪽을 클릭하면 파일 선택을 할 수 있는 화면이 출력된다. 원하는 파일을 선택하면 업로드가 진행된다.
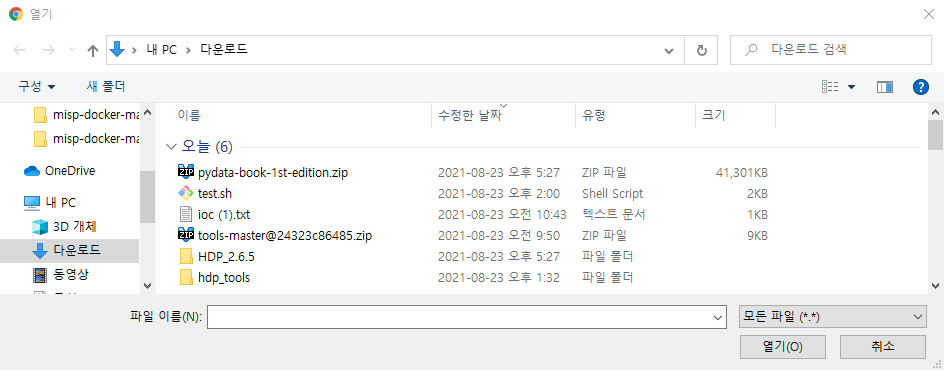
정상적으로 업로드 된 것을 확인할 수 있다.

업로드하려는 데이터 파일 개수가 많은 경우
Ambari는 단일 파일만 업로드 되고 다중 파일이나 폴더는 업로드 되지 않는다. 따라서 다음 방법으로 진행해야 한다.
데이터 파일 복사
미리 생성한 테스트 데이터를 압축한다. (ex. HDPTestData.zip)
압축한 테스트 데이터 파일을 scp 명령을 이용하여 HDP Sandbox의 루트 경로로 복사한다.
$ scp -P 2222 HDPTestData.zip root@sandbox.hortonworks.com:/
# 각 항목은 다음을 의미한다.
# -p 2222 - 파일 전송에 사용할 포트번호
# HDPTestData.zip - 전송할 파일의 경로와 이름
# root@sandbox.hortonworks.com - 파일을 저장할 HDP Sandbox의 계정과 URL
# :/ - HDP Sandbox에 파일을 저장할 경로
# scp 명령에 -r 옵션을 주면 폴더도 복사 가능하다.
HDP Sandbox Shell 로그인
HDP Sandbox의 SSH (Secure SHell)를 이용하여 HDP Sandbox의 쉘에 로그인한다.
터미널을 이용하는 경우
SSH (Secure SHell)을 이용하여 HDP Sandbox의 쉘에 로그인한다.
$ ssh root@sandbox.hortonworks.com -p 2222
# 각 항목은 다음을 의미한다.
# root@sandbox.hortonworks.com - 접속하려는 HDP Sandbox의 계정과 URL
# -p 2222 - SSH 포트번호
Shell Web Client를 이용하는 경우
HDP Sandbox의 Shell-in-a-box를 사용하려면 아래 URL에 접속한다.
http://sandbox.hortonworks.com:4200
파일 압축 해제
HDP Sandbox Docker 컨테이너의 루트 경로에 복사한 압축 파일의 압축을 해제한다.
$ unzip HDPTestData.zip
# HDPTestData 디렉토리가 생성되고 압축이 해제된다.
데이터 파일 HDFS 업로드
HDP Sandbox Docker 컨테이너의 루트 디렉토리에 생성 된 HDPTestData 디렉토리를 HDP Sandbox의 HDFS에 업로드한다.
- HDFS의 루트 디렉토리에 HDPTestData 폴더가 업로드 된다.
- Ambari의 File View를 이용해서 정상적으로 업로드 되었는지 확인한다.
$ hadoop fs -put /HDPTestData /
# 각 항목은 다음을 의미한다.
# hadoop fs - Hadoop 파일 시스템 명령어를 사용한다.
# -put - 파일을 업로드한다.
# /HDPTestData - 업로드하려는 파일의 경로와 이름
# / - 파일을 저장할 HDFS의 경로
데이터 파일 이동
HDFS에 업로드한 디렉토리와 파일들을 아래 명령어로 원하는 위치에 배치한다.
# 파일/디렉토리 이동/이름 변경
$ hadoop fs -mv 원본파일 대상파일
# 파일/디렉토리 복사
$ hadoop fs -cp 원본파일 대상파일
# 파일 삭제
$ hadoop fs -rm 대상파일
# 디렉토리 삭제
$ hadoop fs -rmdir 대상디렉토리
또는 Ambari의 Copy, Move 기능을 사용한다.
하위 디렉토리를 보고자 할때는 검은색 폴더 아이콘을 클릭한다.
로컬 데이터 삭제
Host PC에서 HDP Sandbox에 복사했던 데이터는 필요 여부에 따라 삭제한다.
$ rm HDPTestData.zip
$ rm -r --force /HDPTestData/*
$ rmdir /HDPTestData
'::: 데이터 분석 :::' 카테고리의 다른 글
| 배포한 HDP Sandbox Docker 이미지 사용을 위한 스크립트 작성 (0) | 2021.09.30 |
|---|---|
| 설정 변경한 HDP Sandbox 2.6.5의 Docker 이미지 배포 (0) | 2021.09.27 |
| HDP Sandbox 2.6.5 접속 관련 참고사항 (0) | 2021.09.23 |
| HDP Sandbox 2.6.5 Docker 설정과 Ambari 로그인하기 (0) | 2021.09.16 |
| HDP Sandbox 소개와 Docker 셋팅 파일 다운로드 (2) | 2021.09.13 |